虚拟化基础
1 什么是虚拟化
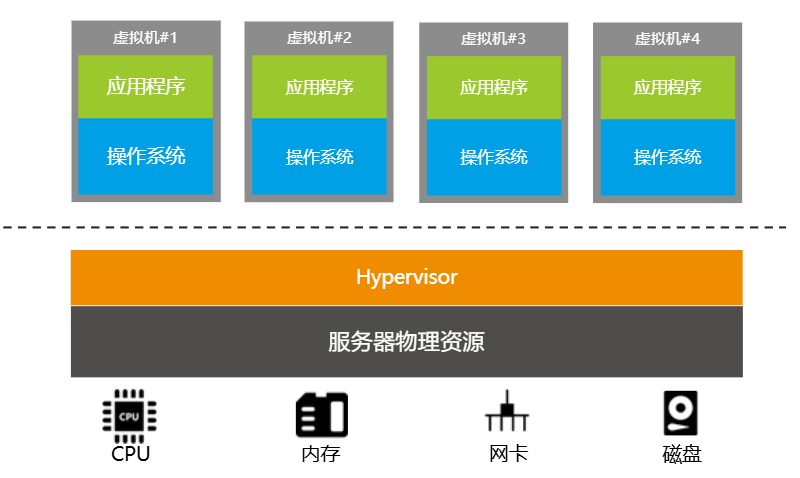
虚拟化是一种资源管理技术,通过软件将计算机的物理资源(如CPU、网络、内存、IO设备等)抽象虚拟为多个逻辑资源,从而分配给多个虚拟机进行使用。
虚拟化分为多种,主要包括服务器虚拟化、应用程序虚拟化、桌面虚拟化等,本次主要学习服务器虚拟化。
该篇笔记主要学习服务器虚拟化,如下图,使用Hypervisor / VMM ( Virtual Machine Monitor)实现虚拟化。
常见的虚拟化包括:CPU虚拟化、磁盘虚拟化、网络虚拟化、IO虚拟化等
2 CPU虚拟化
2.1 CPU架构
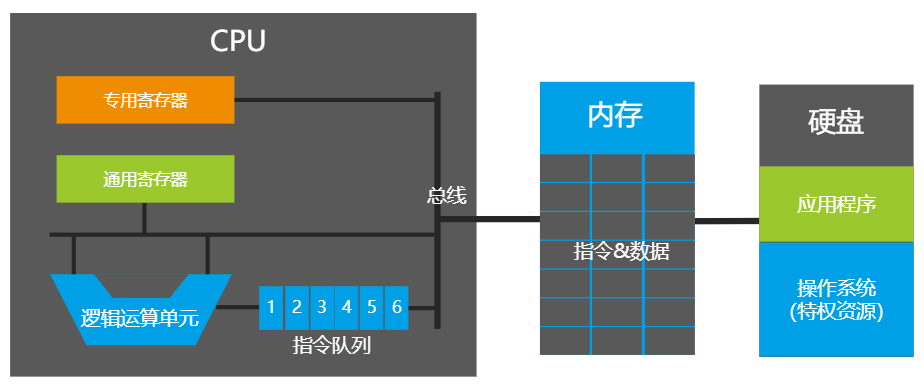
上图是简化的CPU架构图,其中通用寄存器用来实现一些基础指令功能,例如AX累加器、BX基址寄存器、CX计数器、DX数据寄存器等;而专用寄存器一般有特殊的用途,例如标志寄存器记录了CPU执行指令过程中的一系列状态;指令寄存器指向了下一条要执行的指令所存放的地址,CPU的工作其实就是不断取出它指向的指令,然后执行这条指令,同时指令寄存器继续指向下面一条指令,因此漏洞攻击中也常将其作为攻击目标,修改其地址从而执行恶意代码;还有段寄存器用于CPU的内存寻址。
2.2 X86-CPU虚拟化
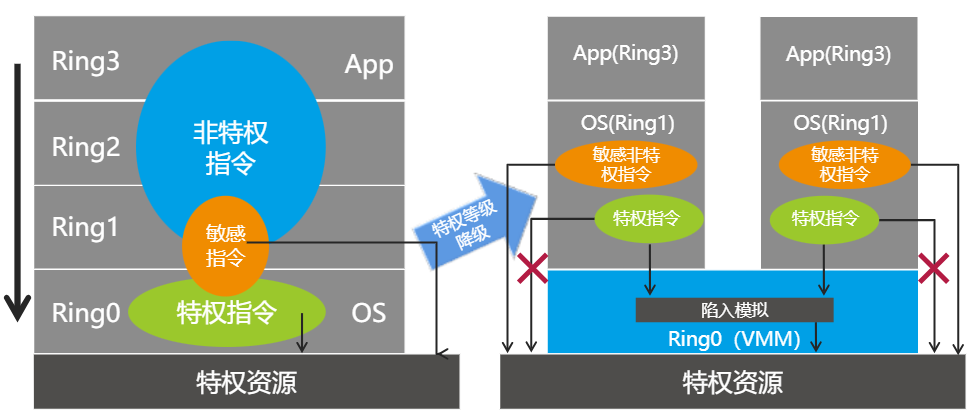
X86-CPU的虚拟化实现如上图所示,X86使用CISC复杂指令集。CPU通过 分级保护域来控制运行级别,又称为CPU环,其中Ring0级别最高,Ring1次之,以此类推。OS(内核)的代码运行在最高级别 ring0 上,可以使用特权指令,控制中断、修改页表、访问设备。应用程序的代码运行在最低运行级别上 ring3 上,不能做受控操作。
同时X86-CPU还存在敏感指令,分为非特权敏感指令(17条)和特权敏感指令:
- 所有 I/O 指令;
- 企图访问或者修改 VM mode 或者机器状态的指令;
- 企图访问或者修改敏感寄存器 / 存储单元的指令;
- 企图访问存储保护系统或内存 / 地址分配系统的指令;
特权指令都属于敏感指令。敏感特权指令在非ring0环境执行时,会触发异常(trap),但敏感非特权指令不会。因此无法使用经典虚拟化。
经典虚拟化如由上图所示,通过“降级”实现,将VMM运行在ring0,OS运行在ring1,当特权指令在ring1执行时,抛出trap(cause a trap),VMM“捕获”trap并模拟执行这些指令,但问敏感非特权指令将会直接执行而无异常报错,导致CPU运行异常。
2.3 虚拟化方案
总的来说,有以下几种虚拟化方案
- 操作系统级别虚拟化(OS-level virtulization)
- 全虚拟化(Full virtualization),又分为硬件和软件
- 类/半虚拟化(Para virtulization)
- 混合虚拟化(Hybrid-Para virtualization)
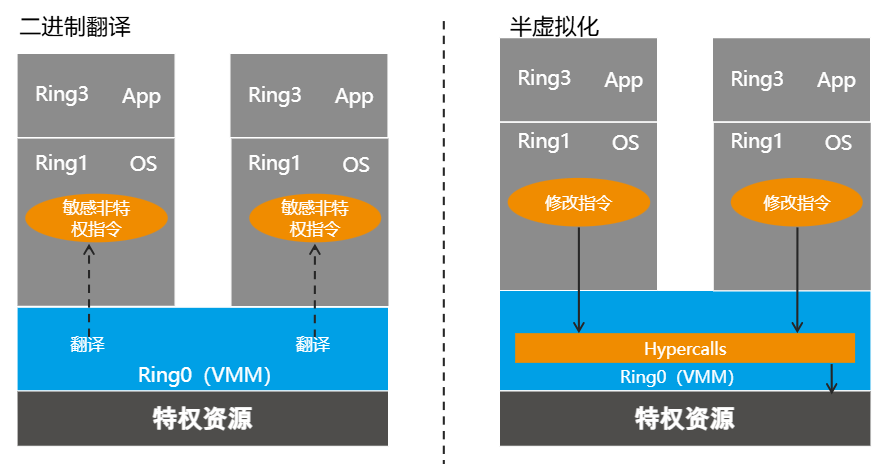
因为之前 x86 的平台的硬件没有从硬件层面支持虚拟化,所以采用纯软件的方式实现 “截获重定向”;该方式为全虚拟化的软件实现方式(左上图)
通过让客户机的特权指令陷入异常,从而触发宿主机进行虚拟化处理的机制来处理,具体的实现方法通过以下两种方式相结合;
- 优先级压缩 (由于虚拟化的引入,应用从 Ring 3 -> Ring 3, 操作系统从 Ring 0 -> Ring 1,VMM 将取代 OS 处于 Ring 0)
- 二进制代码翻译(优先级压缩并不能很好的处理截获所有的特权指令,需要通过二进制翻译来扫描修改客户机的二进制代码,来将这些难以虚拟化的指令转换为支持虚拟化的指令)
右上图为半虚拟化,OS经过VMM重新定义的API接口进行修改,将直接执行敏感非特权指令,修改为调用这个特殊的API
全虚拟化的软件实现,存在性能损耗和实现复杂的缺点,而半虚拟化存在兼容性差的问题,需要每个OS进行对应修改。因此,从CPU硬件层面推出了全虚拟化的硬件实现方式
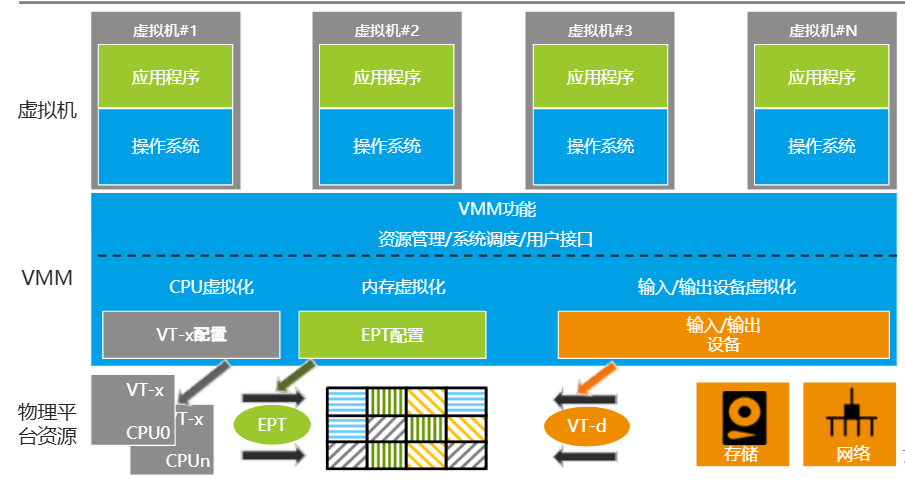
Intel的VT-x和AMD的AMD-V,实现了物理设备的虚拟化,提供了对特殊指令截获重定向的硬件支持,具体实现方式如下:
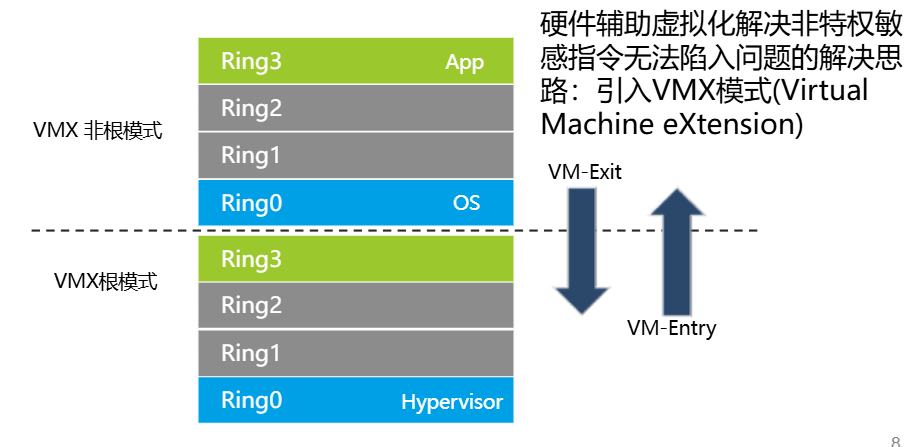
 新增了CPU的模式,Intel为root mode(VMM)和non-root mode(guest);AMD为host mode 和 guest mode,尽管客户机OS认为自己在ring0,实际上它跑在non-root mode的ring0上
新增了CPU的模式,Intel为root mode(VMM)和non-root mode(guest);AMD为host mode 和 guest mode,尽管客户机OS认为自己在ring0,实际上它跑在non-root mode的ring0上
VMCS中定义了VM执行控制区域,当VM想执行敏感指令(无论是敏感特权还是敏感非特权)时:
- 该指令被 VMCS(虚拟机控制结构)配置为 需要拦截,则 CPU 触发 VM Exit。
- CPU 自动切换到 Root Mode,把控制权交给 VMM。
- VMM 在 Root Mode 下模拟或处理该指令。
- VMM 通过 VM Entry 把控制权交回 Guest OS。
如此一来,既能让OS不需要做修改,同时通过硬件层面保证了性能不被过多损耗
具体来说,VMCS使用指令虚拟化来实现状态的切换和对VM的控制

以VT-x为例,Intel 引入了一组新指令,分为两类:
- VMX 管理指令(由 VMM 在 Root Mode 使用)
VMXON:进入 VMX 操作模式(启用虚拟化扩展)。VMXOFF:退出 VMX 操作模式。VMLAUNCH:启动一个虚拟机(Guest OS)。VMRESUME:恢复一个暂停的虚拟机(在它执行过 VM Exit 之后)。VMCALL:提供 Guest → VMM 的调用通道,相当于虚拟化环境里的 “Hypercall”,给VM一个 主动进入根模式的接口或者说向VMM请求服务VMCLEAR:
- VMCS 操作指令
VMPTRLD/VMPTRST:加载/存储 VMCS 指针。VMREAD:读取 VMCS 中的字段值(例如 Guest 的寄存器状态)。VMWRITE:写入 VMCS 字段。
VMLAUNCH:第一次启动虚拟机时用,Guest 进入 Non-root Mode 执行。
VMRESUME:在 Guest 发生 VM Exit 之后,用它把 Guest 恢复执行。
VM Exit:当 Guest 执行敏感指令(如
MOV CR3、HLT、IN/OUT等),CPU 会触发 VM Exit,把控制权交给 VMM。VM Entry:由
VMRESUME或VMLAUNCH指令触发,把控制权交回 Guest。
3 内存虚拟化
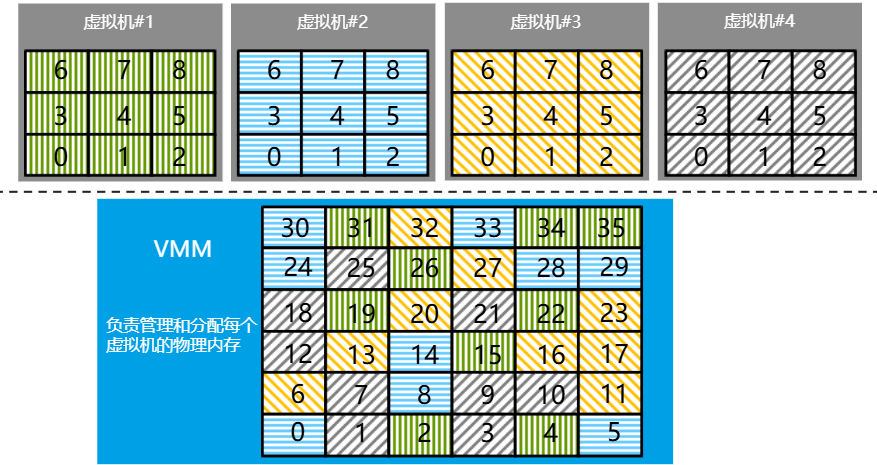
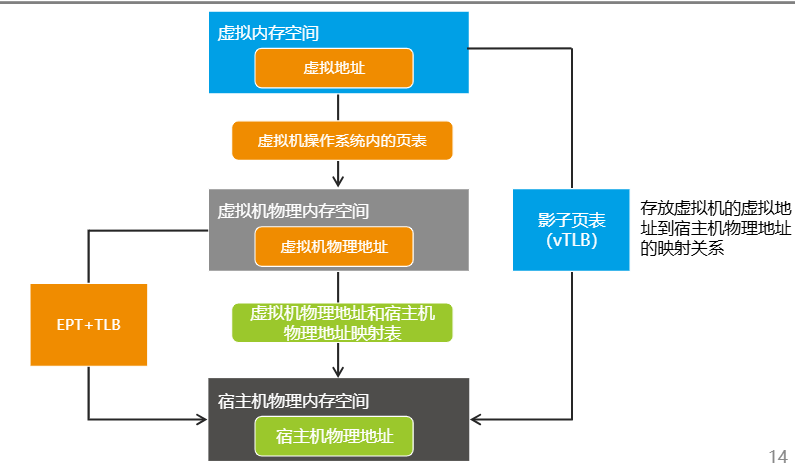
VM的内存地址与宿主机的物理内存地址需要一个映射过程。 传统来说,VM使用虚拟内存空间(GVA),存在一个地址,使用VM的OS页表映射到VM“物理”内存中的物理地址(GPA),接着通过VM”物理“地址与宿主机物理地址映射表,最终映射到宿主机物理的内存地址(HPA)。但如果每次使用都需要这样查一次映射表,性能有限,消耗资源。
因此为了提高第二次及后续访问效率,使用影子页表,存放VM的虚拟地址到宿主机物理地址的映射关系,但每台VM需要有一张影子页表来记录对应映射关系,比较消耗资源。 图中vTLB本质上是 Hypervisor 模拟的 TLB 缓存,用于加速”查找“。
最终,又是CPU厂商推出了硬件支持虚拟化,从根本上给出了解决方案,使用EPT(intel)和RVI(AMD)技术,在硬件层面支持 两级页表映射:
- Guest Virtual Address (GVA) → Guest Physical Address (GPA)(由客户机页表管理)
- Guest Physical Address (GPA) → Host Physical Address (HPA)(由 Hypervisor 提供的 EPT 管理)
- 硬件 TLB 支持缓存多级转换结果,大大减少性能损耗。
4 IO虚拟化
网卡虚拟化:SR-IOV将一张物理网卡虚拟化出多张虚拟网卡
VT-d:将网卡分配给虚拟机

5 虚拟化方案
市面上流行的一种方案是QEMU+KVM,下面简述一下其基本工作原理

KVM作为Linux内核,使用intel/amd.ko的驱动、结合CPU 的硬件虚拟化扩展,执行虚拟机指令。而QEMU作为用户态进程,负责创建虚拟机、分配内存、模拟外设(磁盘、网卡、显卡等),使用/dev/kvm接口调用KVM虚拟化模块;使用EPT、SR-IOV等技术对内存、网卡和存储设备进行虚拟化 用户模式中的Tomcat用于为用户提供web界面对虚机进行管理、操作;libvirt用于管理KVM
 VM的运行流程如上,首先在ring3(app层)的web(tomcat)界面创建并运行虚拟机,QEMU会在HVA里(HVA是QEMU进程向宿主机申请的一块内存)申请一块内存分配给VM,作为VM的“物理”内存(也就是GPA),同时会生成HVA到GPA的映射表,最终由KVM内核将HVA转为HPA,完成GVA到HPA的映射;接着KVM在ring0内核模块中获取到创建虚机的请求,创建对应的VMCS,同时运行虚拟机,执行VMLUANCH指令,并进入VMX非根模式,执行对应指令,当VM发生异常(例如执行敏感操作)或执行IO操作时,退出非根模式,在根模式下进行对应操作,若为IO操作,则通过QEMU模拟进行操作再将结果返回给KVM内核,最终再回到非根模式。
VM的运行流程如上,首先在ring3(app层)的web(tomcat)界面创建并运行虚拟机,QEMU会在HVA里(HVA是QEMU进程向宿主机申请的一块内存)申请一块内存分配给VM,作为VM的“物理”内存(也就是GPA),同时会生成HVA到GPA的映射表,最终由KVM内核将HVA转为HPA,完成GVA到HPA的映射;接着KVM在ring0内核模块中获取到创建虚机的请求,创建对应的VMCS,同时运行虚拟机,执行VMLUANCH指令,并进入VMX非根模式,执行对应指令,当VM发生异常(例如执行敏感操作)或执行IO操作时,退出非根模式,在根模式下进行对应操作,若为IO操作,则通过QEMU模拟进行操作再将结果返回给KVM内核,最终再回到非根模式。
| |